Je regardais depuis quelques temps avec grand intérêt le travail de Cécile Georges, une artiste qui travaille le son et l’image avec des procédés automatiques, explorant les défauts et les glitches des outils du numérique. En discutant avec elle, j’ai appris qu’il lui arrivait d’utiliser audacity pour charger une image au format bmp, afin d’appliquer dessus des algorithmes de traitement de son avant de sauver le fichier pour le visualiser. L’occasion de produire des distorsions, d’observer, d’expérimenter plein de choses. Son processus imposait des étapes de manipulation attentives, pour ne pas casser les entêtes du fichier image, cette partie qui permet de relire ensuite le fichier comme une image.
En discutant ensemble, on a convenu que ça pourrait être facilité, voire même que l’on pourrait proposer le chemin inverse : lire un fichier son depuis un logiciel de traitement d’images, lui appliquer là aussi des filtres et des effets, puis réécouter le fichier ensuite.
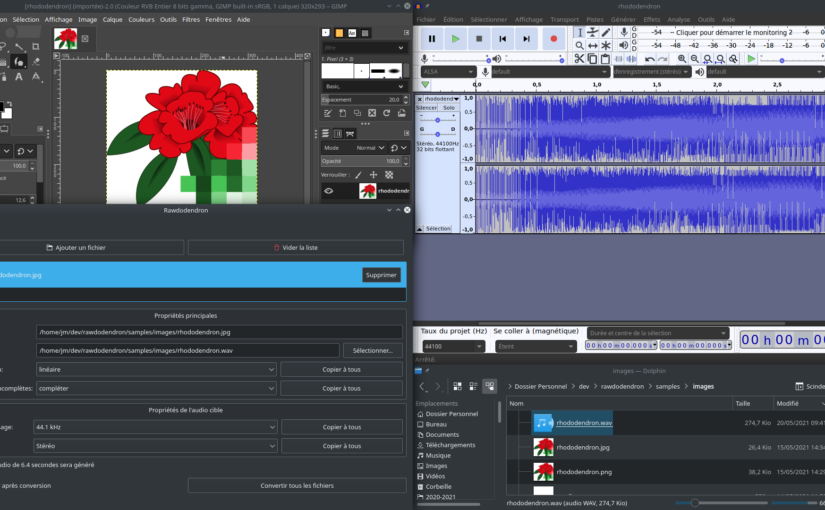
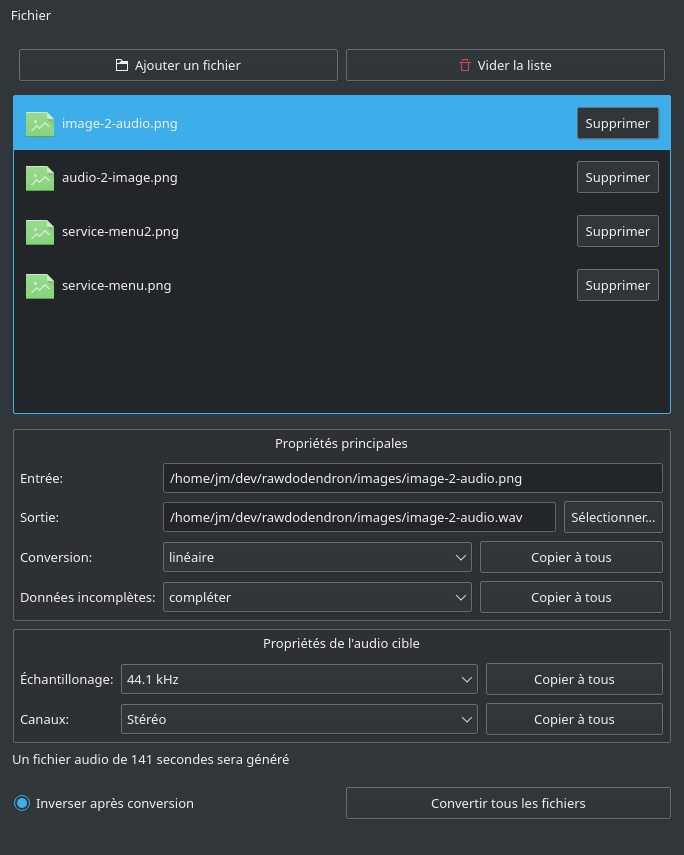
J’ai donc pris quelques jours, un week-end étendu, et j’ai écrit en python un logiciel, rawdodendron, qui permet de faire de la transformation automatique de fichiers audio vers image, et réciproquement. Le code source est bien sûr disponible en ligne sous licence libre, et j’ai produit une courte vidéo de démonstration, où l’on écoute un son modifié grâce à gimp.
Dans l’autre sens, on peut bien sûr convertir un fichier image en son, puis le modifier avant de revenir dans le visible.

image originale, logo du logiciel 
image obtenue par compression du son 
image obtenue par réverbération 
image obtenue avec un autre réglage de réverb
Le logiciel est donc composé d’une interface où l’on peut glisser/déposer des fichiers, puis modifier les réglages de la conversion avant de générer les fichiers de l’autre modalité. L’interface est réglée pour automatiquement préparer la conversion inverse. Cela permet de faire de rapides allers/retours entre les deux modalités, pour expérimenter un maximum d’algorithmes différents.
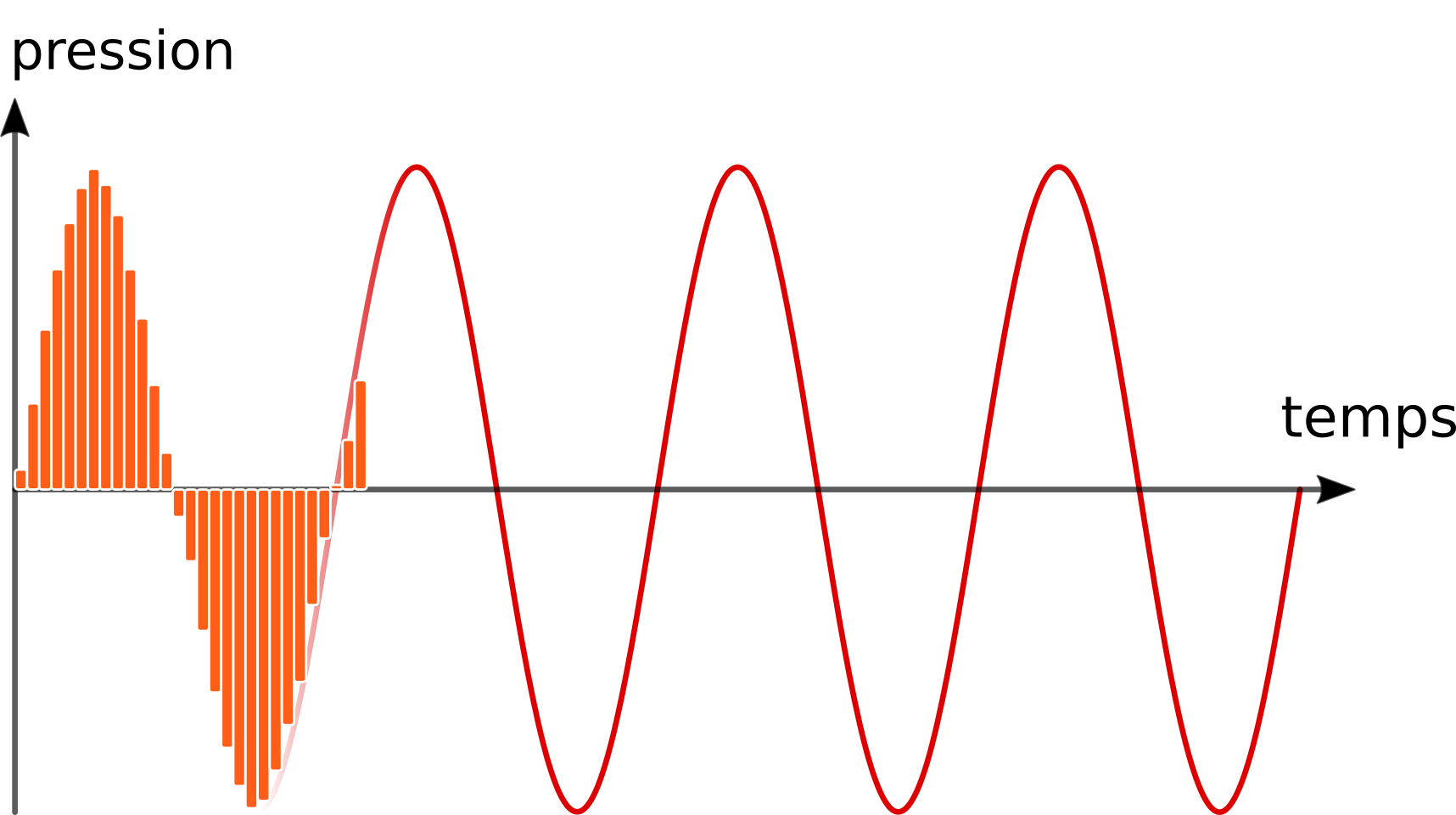
D’un point de vue technique, l’outil manipule des images composées de pixels (png, jpg, etc), et des sons numériques (mp3, wav, flac, etc). J’en avais déjà parlé dans un article dédié à la synthèse de son additive, un son peut être modélisé par une série de pressions/décompressions, et la manière de le stocker numériquement est de le découper selon une fréquence très rapide (on parle par exemple de 44100 enregistrements par seconde pour le son d’un CD). On va alors stocker pour chacun de ces échantillons le degré de compression/décompression :
Ce sont chacun de ces échantillons qui seront convertis en pixels avec rawdodendron. Car de la même manière que l’on code cette pression/décompression à l’aide d’un entier (compris entre ‑127 et 128 dans la version la plus simple), chaque pixel est codé par un entier entre 0 et 255 (dans sa version la plus standard). Rawdodendron va donc balayer l’image de gauche à droite puis de haut en bas, et traduire brutalement (d’où le raw de rawdodendron) les échantillons sonores en son, et réciproquement.
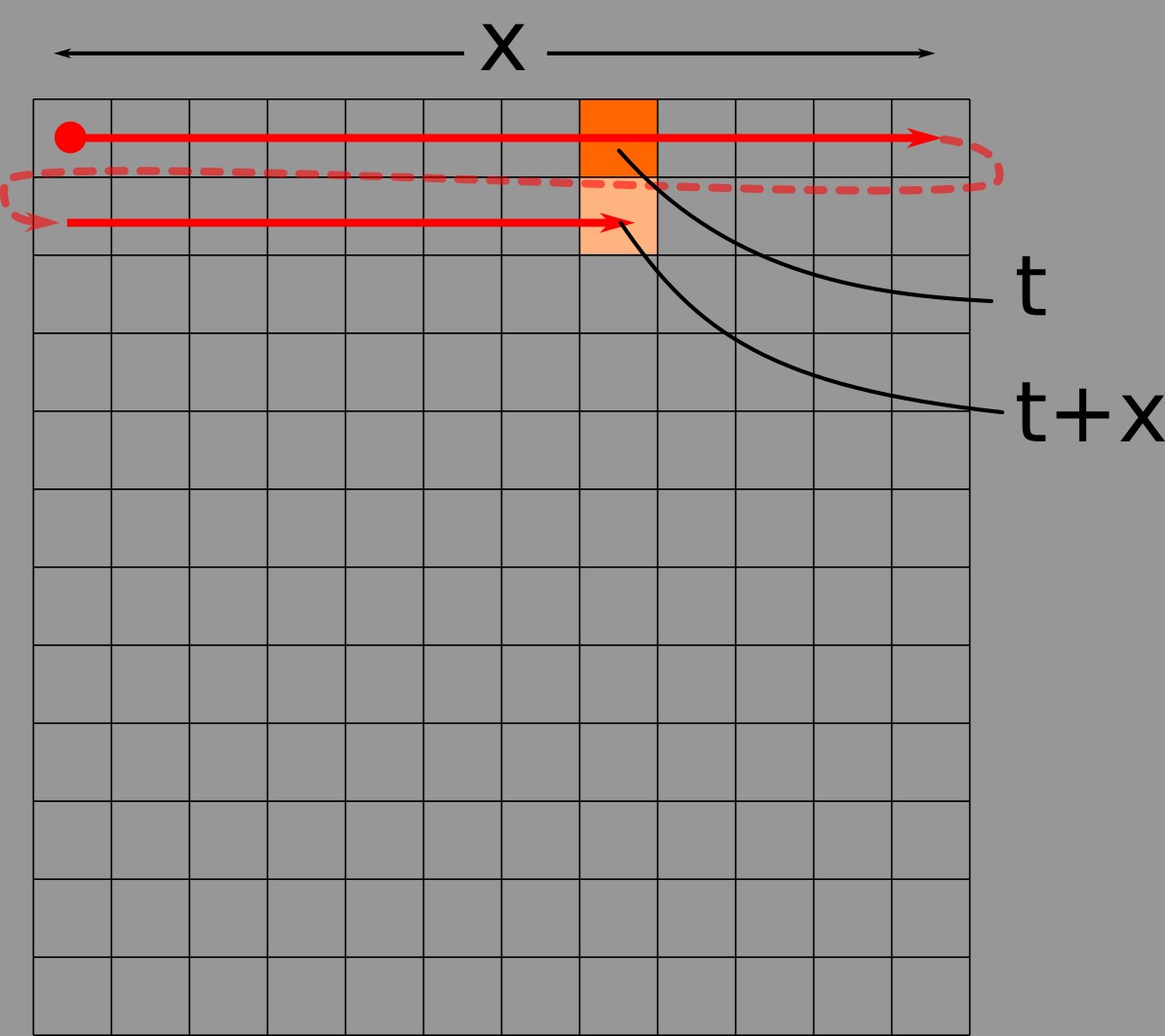
Dans l’image ci-dessus, on voit bien que deux pixels qui sont adjacents peuvent se situer à de moments différents du son. La largeur de l’image (ici notée x) entraîne un genre de « repliement temporel », le pixel t étant adjacent au pixel t+x. On comprend donc que la largeur de l’image générée à partir d’un son soit un paramètre important, car souvent les filtres image modifient les pixels en fonction de leurs voisins, qu’ils soient sur la même ligne horizontale ou non.
Dans l’explication ci-dessus, je n’ai parlé ni du fait que les fichiers audio étaient souvent stéréo, et que les fichiers image n’étaient pas juste noir et blanc. Il y a donc 2 valeurs par échantillon de son, un pour l’oreille droite, l’autre pour l’oreille gauche. Sur les images, on a 3 valeurs (voire 4) pour chaque pixel, afin de composer le mélange rouge/vert/bleu (et parfois transparent). Le balayage va donc considérer chacune des valeurs de pixel avant de passer au pixel suivant, de même que considérer chaque canal audio de l’échantillon avant de passer au suivant. Cela peut entraîner des comportements peu intuitifs, et je conseille aux débutants avec ce logiciel de choisir des sons mono et des images en noir et blanc (et enregistrés en niveau de gris) pour réussir à comprendre un peu ce qui se passe.
Enfin, il est intéressant de noter que les formats mp3 et jpg, conçus chacun pour réduire la taille des fichiers en réduisant la qualité des données sans que cela ne soit trop perceptibles réduisent très perceptiblement les données dans l’autre modalité (le mp3 est particulièrement agressif à l’œil). Privilégiez donc les formats non destructifs comme la flac et ou le png.